#
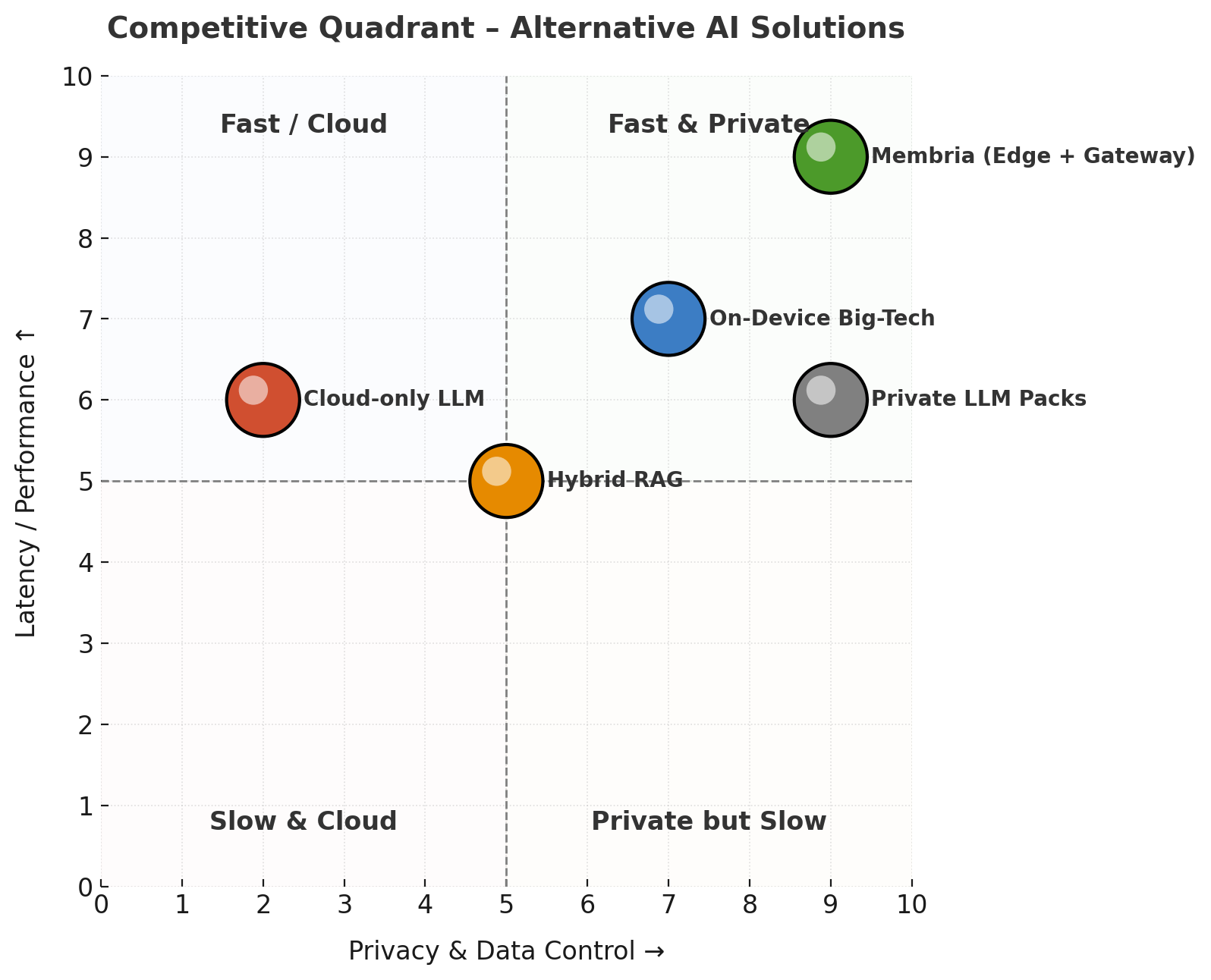
Membria vs. Alternative AI Solutions
#
Key Take-aways
- Economics flip: Membria shifts costs to the edge and turns cloud usage into a pay-per-consult micro-fee, while pure-cloud vendors fight margin erosion.
- Privacy by default: Only Membria and Private LLM Packs keep all user data on-device without manual setup.
- Latency wins UX: Sub-300 ms offline answers feel instant; cloud calls stay 1-3 s even on fast links.
- Future-proof routing: Gateway design lets developers mix local skills with frontier experts via a single API, no prompt-gymnastics needed.
#
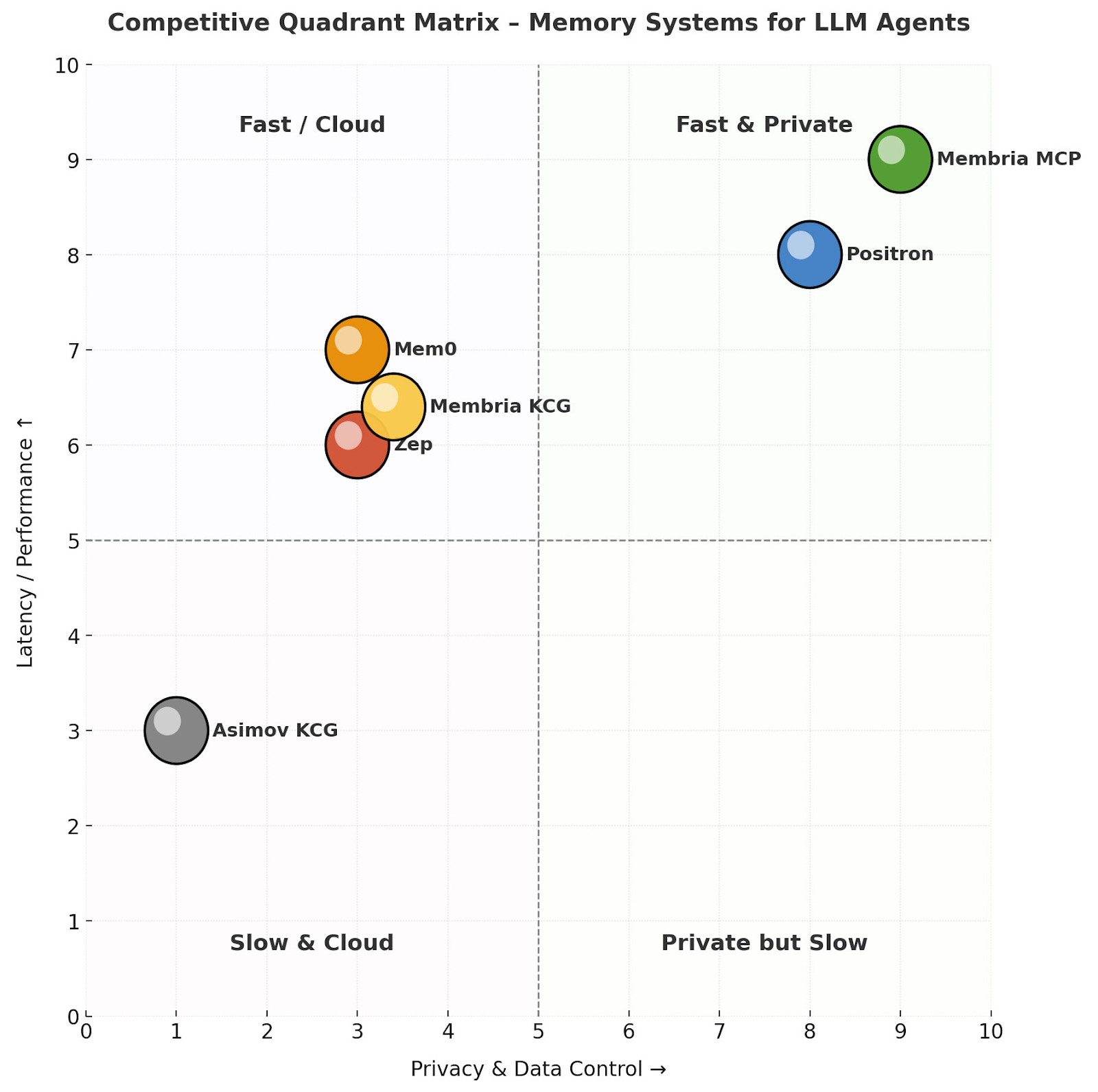
Memory Systems for LLM Agents
#
Key Findings
- Membria MCP is the only option combining an on-device swap-context store and hybrid routing to cloud experts, minimising token overhead while retaining frontier reasoning on demand.
- Privacy spectrum: full offline privacy (Membria MCP, Positron) → vendor-cloud (Mem0, Zep) → public verifiable graph (Asimov KCG).
- Economics: Membria’s hybrid model removes recurring fees for users and slashes GPU cap-ex for providers, unlike cloud-only Mem0/Zep.
- Latency & UX: Membria and Positron deliver sub-300 ms offline answers; Mem0/Zep are fast but depend on connectivity; Asimov KCG suffers multi-second latency due to Web3.
- Developer effort: easiest drop-in: Zep/Mem0; best flexibility: Membria Gateway SDK; highest barrier: Asimov KCG & Positron.
Bottom line: For a private, cost-efficient, low-latency memory layer that still lets agents tap frontier reasoning when needed, Membria MCP is the most balanced solution in 2026.