#
Decentralized Storage and Governance Over On-Device AI

#
1. Abstract
Actiquest On-Device AI (running in the AI Live Pod) is the complex of Vision/LMM and NLP neural models brings next-generation edge intelligence to users’ devices by combining efficient local inference with a robust Compute-to-Data paradigm. Rather than pulling massive datasets into centralized servers for training, Actiquest stores and governs these datasets on the Internet Computer (ICP)—enabling a decentralized, community-driven approach to data handling. This litepaper outlines how these components integrate to deliver private, up-to-date, and decentralized AI solutions, including the process of delivering the best pre-trained models to end-user devices.
#
1.1. Purpose
The primary goal is to define a modular, secure, and transparent method for storing and managing AI model artifacts (e.g., weights, configuration files) in the Actiq ecosystem. This includes guidelines for chunked storage, version control, and access control, ensuring that both public and proprietary models can be handled effectively on the Internet Computer (ICP) or via hybrid solutions.
#
1.2. Scope
This document applies primarily to final or frequently accessed model checkpoints—the files needed for on-device inference and iterative improvements. It does not focus on the broader management of raw training datasets or massive data pipelines, which involve different considerations around scale, labeling, and compute. Instead, the scope here is to provide clarity on:
- Chunking & Uploading AI model files to canisters or cloud/decentralized storage.
- Governance workflows for approving and versioning new checkpoints.
- Security practices like hashing, encryption, and licensing for private or commercial models.
#
1.3. Key Features
Chunked Storage Large model files are split into smaller pieces to accommodate canister or network limits, with each chunk hashed for integrity checks.
Immutable References Each version of the model is associated with a manifest and global hash, preventing unauthorized tampering or silent overwrites.
DAO / SNS-Based Governance When combined with the Actiq DAO, updates to the “official” model version require community proposals and voting—ensuring transparency and consensus.
Selective Access Control Public/open-source models can be freely retrieved, while private or commercial models are encrypted and licensed, requiring a key or DAO permission to decrypt.
Clear Versioning Model checkpoints follow a versioned registry (e.g., v1.0, v2.0, etc.). Users and devices can easily identify, roll back, or upgrade to a new model release.
These features form the foundation of the Actiq model-storage workflow: offering reliability, security, and scalability, while integrating seamlessly with on-device AI use cases and decentralized governance models.
#
2. Introduction
#
2.1 Background
The rapid ascent of artificial intelligence (AI) in domains such as computer vision, natural language processing, and personalized recommendations has often hinged on centralized data pipelines. Traditional AI workflows store large volumes of data in monolithic data centers, train models on powerful, centralized compute clusters, and then deliver these models to end users—often via cloud APIs. However, this model presents several shortcomings:
- Privacy Concerns: Centralized datasets can be vulnerable to leaks or unauthorized usage.
- Single Points of Failure: A single entity controlling data and model access can impose censorship, raise fees, or unilaterally change usage terms.
- Limited Community Involvement: Contributors (e.g., data owners, labelers, or subject-matter experts) typically have little direct input into model curation or governance.
- Scalability & Latency: Constantly streaming data to and from the cloud can be costly and introduce performance bottlenecks, especially for real-time or sensor-based applications.
#
2.2. Vision for a Decentralized On-Device AI Ecosystem
Instead, a decentralized architecture can address many of these concerns by distributing data storage, governance, and inference. We propose the Internet Computer (ICP) as the trustless backbone to store and manage data, while allowing:
On-Device Local Inference. Models run locally on user devices or edge hardware, ensuring low-latency, privacy-preserving AI.
Community Governance. A decentralized autonomous organization (DAO) or Service Nervous System (SNS) on ICP oversees dataset curation, usage terms, and revenue distributions—enabling transparent decision-making.
Compute-to-Data. Data remains encrypted and within canisters; compute providers request access to train or fine-tune models. Once approved, the data is decrypted for that specific job (off-chain or on specialized subnets).
Immutable Logs & Versioning. All changes to datasets, model checkpoints, and governance parameters are recorded on the ICP, guaranteeing tamper-proof auditability.
#
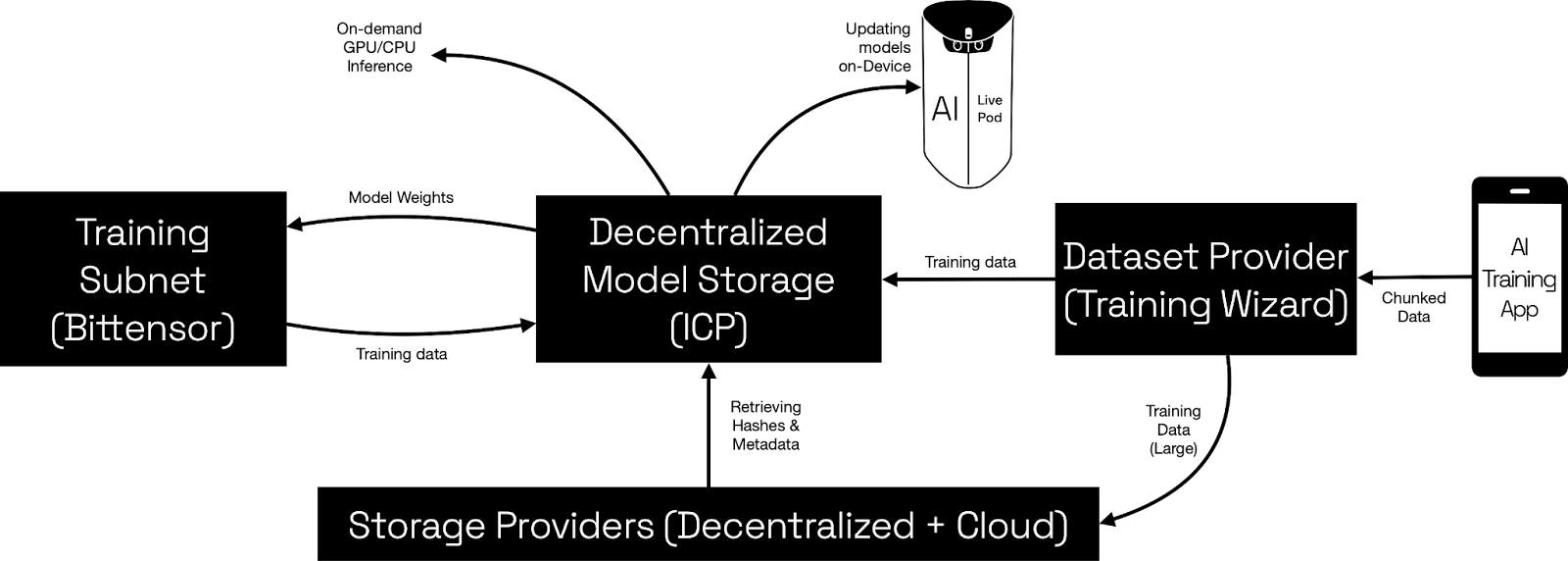
2.3. Where Are AI Models Stored?
#
2.3.1. On-Chain (Canisters)
- Smaller to medium-sized models (e.g., up to ~GB scale) can be stored directly in ICP canisters.
- Chunked Approach: If a model exceeds a few hundred MB, it must be split into chunks (<1 MB each) to stay within canister message size limits. A “file canister” or “multi-canister” structure indexes these chunks.
#
2.3.2. Off-Chain References.
For very large LLMs or Vision Transformers (multi-GB or TB scale), hybrid storage is recommended:
- References (hashes, metadata) in a canister,
- Actual file chunks in a specialized decentralized network (e.g., Arweave, Storj, or IPFS) or in cloud.
- The canister holds the integrity hash of each chunk so that anyone fetching it can verify authenticity.
#
3. Uploading Models
#
3.1 Chunking & Hashing
#
3.1.1. Chunk File
- A client-side script divides the model file (e.g.,
model_weights.bin) into ~1 MB chunks.
#
3.1.2. Hash Each Chunk
- Compute a cryptographic hash (e.g., SHA-256) per chunk. Store these in a manifest (JSON or similar).
#
3.1.3. Upload
- For on-chain, each chunk is sent to a file canister with a reference ID.
- For off-chain, each chunk is uploaded to a decentralized storage layer.
#
3.1.4. Record in Canister
- The manifest (list of chunk hashes + a global file hash) is stored in a “Model Registry” canister.
- Optionally store the entire chunk data in canister stable memory (if small enough).
#
3.2 Encryption (Optional)
- Private/Commercial Models may be encrypted using a user/DAO-held encryption key.
- Client-Side Encryption ensures no plaintext is ever stored in the canister or external storage.
- The encryption key can be kept secret by the model owner or managed by a DAO canister (under governance rules).
#
3.3. Versioning & Updates
#
3.3.1. Immutability vs. Updates
- Once chunks are uploaded, they are immutable—you cannot overwrite an existing chunk.
- New Version = new set of chunks with a different manifest.
#
3.3.2. Manifest Registry
- The “Model Registry” canister keeps track of multiple versions:
v1.0,v1.1,v2.0, etc. - A pointer or “current version” field indicates which version is the official release.
#
3.3.3. DAO/SNS Approval
- If using Actiq’s DAO system, each new version might require a proposal and vote.
- Once approved, the pointer updates to the new version, and devices automatically see an update.
#
3.4. Cost consideration
- Storing large amounts of data in canister stable memory requires cycles.
- Off-chain references (Arweave/IPFS) can be more cost-effective for huge models; the ICP canister is used as a “single source of truth” for verifying references.
#
4. Architectural Overview
#
4.1 Core ICP Design
#
4.1.1. Canisters
- Smart contracts on ICP, hosting both code (WebAssembly) and data (stable memory). They can hold structured data, files, and application logic.
- Canisters are powered by “cycles,” ensuring a predictable cost model.
#
4.1.2. Boundary Nodes
- Edge gateways that serve user-facing requests (e.g., HTTP calls) and route them to the correct canister. They can also cache static content, partially acting like a lightweight CDN.
#
4.1.3. Subnet Architecture
- The Internet Computer network is composed of subnets (groups of replica nodes) which can collectively run canisters. This design ensures redundancy and decentralization.
#
4.1.4. Service Nervous System (SNS)
- A framework that transforms a canister-based application into a community-governed DAO. Token holders can propose and vote on code updates, data changes, fees, or rewards distribution.
#
4.2 Advantages for AI Data Storage and Governance
#
4.2.1. Low On-Chain Storage Cost
- The ICP’s model, while not as inexpensive as traditional cloud storage, is comparatively cost-effective versus other blockchains that might charge significant gas fees for data.
#
4.2.2. DAO Governance Out-of-the-Box
- Using SNS, developers can quickly set up a governance token, proposal system, and treasury logic—ideal for datasets that require curation, licensing, or community-based moderation.
#
4.2.3. Stable Memory for Large Data
- Each canister can store up to 4GB of stable memory (with possible future increases), enabling direct storage for moderate-sized models or datasets. For larger ones, chunked approaches or multi-canister architectures are used.
#
4.2.4. Global Accessibility
- The Internet Computer is designed to be globally accessible, with boundary nodes offering near-universal coverage for data retrieval and dApp access.
#
4.3 Storage Layer
#
4.3.1. Chunked Data Canisters
- File-Style Canisters: For vision datasets (images, videos), large text corpora, or sensor logs, developers can implement chunked storage. Each chunk is typically <1MB, stored in stable memory.
- Metadata Registry: A separate canister that maps dataset IDs to chunk references (hashes), file sizes, and optional encryption keys or IPFS-like references.
#
4.3.2. Off-Chain Hybrids
- Some cases may be more effective a hybrid approach, where large or infrequently accessed data is stored using centralized cloud services. The ICP canister then holds references, licensing info, and verifies data integrity with stored hashes.
#
4.4 Governance Layer
#
4.4.1. DAO (SNS) or Custom Governance
- SNS: A built-in approach where the Internet Computer automatically sets up a governance token, neuron-based staking, and proposal logic. The dApp’s community can decide on data updates, usage fees, or distribution of revenues.
- Custom DAO: Developers can also code a custom governance canister in Rust or Motoko, giving them more tailored logic (e.g., specialized curation markets, nested proposals, or fine-grained permission controls).
#
4.4.2. Proposal Lifecycle
- Proposal Creation: A user or recognized contributor adds a proposal to ingest a new dataset, change a licensing fee, or incorporate a new model checkpoint.
- Voting: Token holders cast votes. If the proposal meets quorum and passes, the canister logic automatically executes the changes.
- Actions: Approved proposals might add new chunk references, pay contributors, or update a model’s version in a specialized canister.
#
4.5. Compute-to-Data Flow
#
4.5.1. Data Remains in Canisters
- Images, videos, bounding boxes, masks (Vision models data) plus text corpora, embeddings, tokenized references (LLM data); stored in chunked file canisters or off-chain data storage, with the ICP canister tracking hashes and metadata.
#
4.5.2. Off-Chain Training Request
- A GPU/ or decentralized CPU node on Bittensor training subnet/ or any other external HPC training environment requests access to the dataset (depends on situation).
- The DAO or data owner grants a decryption key if the proposal is passed or the entity meets certain criteria (e.g., paid a licensing fee).
#
4.5.3. Secure Training
- The HPC training environment decrypts and processes the data locally.
- Zero-knowledge proofs or secure enclaves may be used to reduce data exposure risks.
#
4.5.4. Model Checkpoint Upload
- After training, the HPC training environment returns a new model checkpoint, which is stored in a “Model Registry Canister” on the ICP, ensuring an immutable record of model evolution.
- The DAO votes again to accept or reject the checkpoint, ensuring community trust.
#
4.6. On-Device AI Delivery
#
4.6.1. Running Models on-Device
- Local Inference devices like AI Live Pod are capable of loading model weights, verifying their authenticity, and running real-time inference with a lightweight model.
#
4.6.2. Fetching Checkpoints
- Device queries the Model Registry Canister for the latest verified checkpoint.
- A cryptographic signature check ensures the model is genuine.
#
4.6.3. Private Computation
- Personal data of AI users (e.g., health metrics, camera images) remains on the device, never shipped to a central server.
- This fosters privacy, reduces latency, and saves network costs.
#
5. Technical Details & Implementation Considerations
#
5.1 Cryptographic Signatures & Hashing
#
5.1.1. Data Upload
- Contributors sign the data with their private key, ensuring authenticity.
- The canister verifies the signature with the contributor’s public key.
#
5.1.2. Model Checkpoint
- Post-training, an aggregator or HPC node signs the final weights. The DAO can verify it was indeed produced by the correct aggregator.
#
5.1.3. Integrity Hashes
- Each chunk or file is hashed (e.g., SHA-256) to detect any tampering. The canister stores these hashes, and any mismatch on retrieval flags an error.
#
5.2. Access Control & Licensing
#
5.2.1. Open Models
- If the model is public (e.g., open-source), the registry canister can expose the chunk references to anyone.
#
5.2.2. Encrypted Models
- If the model is private or commercial, each chunk is encrypted with a symmetric key.
- Only users or devices with the correct decryption key can read the chunks.
#
5.2.3. DAO / SNS Licenses
- A governance canister may require purchasing a license token or passing a DAO proposal before granting the decryption key.
- The canister can store an access table mapping “Principal -> Allowed to Download.”
#
5.2.4. Payment & Royalties
- The system can integrate a payment flow (e.g., user sends tokens/cycles), then the canister releases the encryption key or grants chunk access.
- The DAO can distribute revenues to model contributors or stakers.
#
5.3 Sustainability & Monetization
#
5.3.1. Cycles
- Each canister on ICP needs cycles to store data and process requests. If the model is fully stored on-chain, cycle usage can become significant.
- Hybrid solutions (metadata on-chain, large chunks off-chain) reduce cycle consumption.
#
5.3.2. Upload Fees*
- If a DAO or developer is uploading multi-gigabyte models, they must carefully plan cycle usage or have a treasury to cover on-chain storage.
- Off-chain solutions might require separate hosting costs, but are typically cheaper at large scale.
#
5.3.3. Revenue Streams
- If models are commercial, license fees or pay-per-download can offset storage costs. The DAO or model creators receive the revenue, fueling further development.
#
5.3.4. Token Incentives
- If the system is governed by an SNS, the governance token can be used to reward contributions, stake in proposals, or trade on open markets.
#
6. Example Workflow
#
6.1. Model Creation
- A developer trains a vision or language model offline.
#
6.2. Chunk & Encrypt
- Split the final weights file into 1 MB chunks, hash them, optionally encrypt them with a key.
#
6.3. Register On-Chain
- Upload chunk references and metadata to the “Model Registry” canister.
- Store the global file hash, version ID, and encryption info.
#
6.4. DAO Approval
- Submit a proposal to label this version as “v1.0 Official.”
- The DAO votes, and if approved, updates the pointer to the new version.
#
6.5. Training on External Training Nodes
- Once approved, an external training node obtains the decryption key, trains or fine-tunes the relevant model.
- Once training yields a strong or improved checkpoint, participants (or the training orchestrator) propose this checkpoint as an “official update.”
- The HPC environment re-uploads the new weights to the Model Registry Canister.
#
6.6. User Retrieval
- An AI Live Pod queries the registry, sees “v1.0 Official,” downloads the chunks, verifies each hash, and decrypts with the provided key (if private).
- The user’s device loads the model for local inference.
#
6.7. Benefits to On-Device AI users
- Users seamlessly benefit from updated AI capabilities (e.g., improved video recognition accuracy or reasoning).
- All model versions are tied to immutable references on the IC, preventing unauthorized or malicious model updates.
- If the community finds a checkpoint suboptimal, they can propose rolling back or adopting a different checkpoint—ensuring user devices always get trusted, high-quality models.
#
7. Retrieval & On-Device Inference
#
7.1. Locate the Model
- A user device (Actiq’s “AI Live Pod”) queries the “Model Registry” canister for the latest version manifest.
#
7.2. Verify Integrity
- The device downloads chunk data (on-chain or from IPFS/Arweave) and checks each chunk hash against the manifest.
- If any chunk hash doesn’t match, the device rejects the file (tampering alert).
#
7.3. Decryption
- If the model is encrypted, the device must retrieve the encryption key from the governance canister or hold it locally (if purchased).
- Once decrypted, the device can load the model into memory for inference.
#
7.4. Version Checking
- The device can confirm the model version is signed or approved by a known DAO.
- This ensures the user isn’t unknowingly running a malicious or outdated model.
#
8. Future Enhancements
#
8.1. Specialized ICP Subnets
- High-Compute Subnets: Future ICP subnets might integrate CPU/GPU resources. This would enable direct on-chain training, reducing reliance on external HPC.
- Large Stable Memory: Ongoing research might push stable memory limits beyond 4GB, simplifying chunking or multi-canister strategies.
#
8.2. Improved DAO Modules
- Curation Markets: Weighted voting or bonding curves for data quality can systematically reward high-value data.
- Automated Label Bounties: Users can earn tokens for labeling unlabeled data, fostering continuous improvement.
#
8.3 Integration with Other Protocols
- Cross-Chain Bridges: Linking ICP canisters to Ethereum, Polkadot, or Bittensor (for decentralized AI training) can broaden the ecosystem.
#
8.4 Secure Enclaves & ZK Computation
- Hardware Enclaves: Potential future subnets or off-chain nodes could offer Intel SGX/TEE-based computation for advanced privacy.
- Zero-Knowledge Training: Methods like fully homomorphic encryption or secure multi-party computation might eventually allow partial training on encrypted data without decryption.
#
8.5 On-Device Model Customization
- Future enhancements to the AI Live Pod could allow partial fine-tuning directly on the device (for small personal datasets), then contributing insights or differential privacy gradients back to the decentralized model storage.
#
9. Security & Integrity Analysis
#
9.1. Data Authenticity
- Mandatory cryptographic signatures for data uploads.
- DAO can slash or penalize malicious data contributors if proven fraudulent.
#
9.2. Immutable Logging
- Any change in the canisters’ state (addition/removal of data, model checkpoint updates) is permanently recorded and visible, preventing unilateral tampering.
#
9.3. Resilience & Redundancy
- ICP replicates canisters across nodes in a subnet. Even if some nodes fail, the data remains intact.
#
9.4. DAO Governance Risks
- As with any token-based governance, whales or large stakeholders could exert heavy influence. Mechanisms like decentralized distribution, reputation scoring, or delegated voting can mitigate plutocratic control.
#
10. Ecosystem Benefits
#
10.1. Scalable & Decentralized
- Scalable models, seamless training routine, decentralized backend, and on-device AI ecosystem, that contains from local AI inference sources can all interoperate without a single point of failure and be more effective in general.
#
10.2. User & Data Owner Trust
- The community (via DAO) collectively audits updates and usage.
- Data owners see a clear trail of where and how their data is used.
#
10.3. High-Quality Model Training
- Bittensor/GPU/HPC AI training ecosystems provides a robust, incentivized environment, attracting resources from around the globe.
- Continual improvements keep models fresh and competitive.
#
10.4. Monetization & Rewards
- Dataset owners, model contributors, and compute providers can earn tokens or revenue shares, making the ecosystem self-sustaining.
#
10.5. On-Device Privacy & Performance
- AI Live Pods run models directly on the user device, ensuring minimal latency and protecting sensitive user data from leaving the device.
#
10.6 Seamless Model Delivery
- End users automatically get updated model checkpoints verified by the DAO, removing friction and ensuring trust in each new release.
#
11. Conclusion
Decentralized storage and governance on the Internet Computer Protocol presents a powerful alternative to traditional, centralized AI pipelines. Actiquest On-Device AI platform merges the best of decentralized technology—immutable data storage, community governance, scalable training, and privacy-preserving inference- all while simplifying model delivery to end-user devices. By adopting a Compute-to-Data approach on the Internet Computer for robust AI development:
- Data owners retain control** of their valuable datasets.
- Developers and participants** are fairly rewarded through DAO-based monetization.
- Users benefit from on-device AI with minimal latency and maximum privacy.
- Model updates are frictionless and tamper-proof, strengthening user trust and system resilience.
The result is a novel AI ecosystem that meets modern demands for transparency, decentralization, performance, and easy model delivery, fostering a more open, trustable, and dynamic future for vision and language AI applications at the edge.
The Actiq approach to model storage balances decentralization, security, and practical costs. By chunking large files, verifying them via hashes, optionally encrypting them for private licensing, and organizing all references in a “Model Registry” canister, we achieve:
- Data Integrity & Transparency: Immutable canisters ensure that datasets and model checkpoints can be audited and are safe from covert manipulation. Models cannot be tampered with silently, thanks to hash checks and version history.
- Flexible Access Control: Public models are freely accessible, while proprietary ones remain encrypted and licensed via the DAO.
- Scalability: Smaller models can live directly on the ICP; huge models can use external storage with an on-chain reference.
- Community-Driven Governance: Proposals and votes ensure that only trusted versions become official, and that revenues or licensing fees flow back to contributors and maintainers. SNS or DAO logic empowers data owners, labelers, and compute providers to shape the platform’s evolution, aligning incentives for high-quality data and model improvements.
- Compute-to-Data Privacy: By encrypting data on the IC, then selectively granting access for off-chain or specialized on-chain compute, sensitive information is protected while still feeding robust training workflows.
- On-Device AI: Delivering newly approved models directly to user devices reduces latency, preserves privacy, and unlocks real-time or offline use cases, especially relevant for wearables, smart home devices, or remote sensors.
By following these guidelines, developers and users can confidently store, retrieve, and update on-device AI models within the Actiq ecosystem, ensuring trust, transparency, and continuous innovation in a decentralized environment.